
ALLIES technical documentation
- ALLIES evaluation plan description of the task
- ALLIES baseline system and tutorial the complete ALLIES documentation
- Documentation of the BEAT platform more information on the BEAT platform
- Conda environment file description required to setup your ALLIES environment
- Beat prefix copy of the baseline diarization system (not required but provide as a reference)
ALLIES licences and development data
- ALLIES challenge rules how to register
- ALLIES licence agreement for development dataset
- ALLIES development data can be downloaded from here
Speech segmentation with speaker clustering, referred to as speaker diarization, is a key pre-processing step for several speech technologies including enriched automatic speech recognition (ASR) or spoken document retrieval (SDR) in very large multimedia repositories. The base accuracy of such systems is of essential to allow applications to perform adequately in real-world environments.
Speaker diarization systems rely on a data driven knowledge and their development requires competences in machine learning as well as a specific domain expertise. Performance of such systems usually degrades across time as the distribution of incoming data moves away from the initial training data (changes in accents, in recording conditions, etc). Thus sustaining system performance across time requires frequent interventions of machine learning experts which makes the maintenance of such system very costly.
The ALLIES evaluation focuses on two ways of freeing speaker diarization systems from the need of machine learning expert interventions upon three axes:
-
Lifelong learning: automatic systems use the stream of incoming data to update their knowledge and adapt to new data across time in order to sustain performance across time;
-
Interactive learning with user initiative: given the current knowledge of an automatic system and a set of documents to process, a human domain expert provides corrections on the automatic systems outputs until the system produces a good enough output.
-
Active learning with system initiative: the system itself asks the domain expert corrections of its diarization hypothesis.
Tasks
All tasks from the ALLIES evaluation are focusing on the speaker diarization task where the question to be answered by the automatic system is: « Who speaks when?«
In the past, many evaluations have been organized to benmark existing systems and the ALLIES avaluation aims at moving toward evaluation of systems in the real world. For this purpose, four flavours of the classical speaker diarization task are considered in the ALLIES evaluation. All participants must participate to one of the core tasks (i.e. Lifelong learning or one of the two flavours of human assisted learning) and optionally to the « Autonomous task that combines all three.
Lifelong speaker diarization
Description
The lifelong learning task simulates the evaluation of an automatic system across time. The system is allowed to update its models using any audio data sent in, creating a better speech model or updating model clusters for instance, and generate a new version of them to handle the next show.
Evaluation protocol
Performance of the system on the development set are returned to the system developer who can modifi the system in order to optimize the system’s performance on the development set. The system developer is free to run as many trials as wanted until the evaluation deadline.
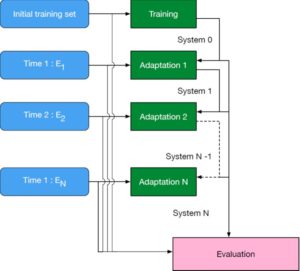
Figure 1: Lifelong evaluation process. Given training set an initial version of the diarization system is trained (System 0). The N documents of the evaluation set are processed chronologically. After each document Et from the test set, the system returns a corresponding hypothesis Ht as well as a new version of the system (System t) that could benefit from knowledge extracted from Et.
Evaluation metric
Note that the performance of the system is now a sequence of DER for each document.
Active learning
Description
In order to allow a fair and reproducible evaluation of automatic systems, as a user in the loop simulator has been developed and integrated on the evaluation plateform. When the system receives an audio file to process, it is allowed to ask the user in the loop one of the following questions:
-
Is the same speaker talking at times (t1) and (t2)
- What are the boundaries of the speech segment containing time
Each question has a cost, and the user will refuse to answer when the per-show cost is reached. In any case the system should eventually give its final hypothesis
Evaluation protocol
The protocol is similar to the one in Lifelong learning except that the system is allowed to perform active learning during its adaptation.
Evaluation metric
Performance of the system is a sequence of DER for each document. The DER is computed on the final version of the hypothesis for each document penalized by the cost of interacting with the user in the loop.
Interactive Speaker diarization
Description
In order to allow a fair and reproducible evaluation of automatic systems, as a user in the loop simulator has been developed and integrated on the evaluation plateform. For each document Dt provided to the automatic system to process speaker diarization, the corresponding reference Rt is provided to the user in the loop simulator.
Once the system provides with a first hypothesis to the simulated user, the user then spontaneously replies by an information of one of the following types:
-
The same speaker is talking at times (t1) and (t2)
- The boundaries of the speech segment containing time (t)
The system should then update the hypothesis and try again. Eventually, when the hypothesis is good or an internal cost is reached, the user will stop this iterative process and the latest hypothesis will be retained as the final one
Evaluation protocol
Automatic systems are trained using the training set as described in the standard protocol. Automatic systems can use the training set documents and references to learn all necessary models and parameters. After training, an initial version of the system, Sys0, is available.
The development set consists of independent documents, which means that time stamps are not used for this task. Each document from the development set is processed independently. For each document, Dt, the automatic system returns a first hypothesis, H0t and an updated version of the system, Sys1t. The hypothesis, H0t is processed by the « user in the loop » which returns a correction to the automatic system. The system returns then a new hypothesis, H1t. This exchange between the system and the « user in the loop » is repeated until the produced hypothesis fully matches the reference Rt or a maximum number of iterations is reached.
Evaluation metric
For each file, a DER will be computed together with the cost of human interaction Required to reach this DER. Given the sequence of penalized scores (DER + penalization cost), the performance of the Lifelong learning systems will be given using an weighed average score that is the mean of all scores computed across time over the \textit{evaluation set} weighed by the duration of the file.
Autonomous system
This task combines lifelong learning, active and interactive learning as described above.
Schedule:
- 14th of December: Announcement of the ALLIES / ALBAYZIN evaluation
- 1st of January until 30th of April: Registration for participants is open
- 1st of March 2020: Release of Development data
- 1st of March2020: Beat platform is open for development
- 1st of June 2020: Evaluation data is released
- 30th of June 2020: Final submission
- End of July 2020: Paper submission deadline
- November 2020: Iberspeech conference in Valladolid