1. Save the features in HDF5 format¶
HDF5 is a portable file format that runs on different platforms and allos easy and readable serialization of data and metadata by using a hierarchical architecture.
HDF5 is the prefered file format in SIDEKIT, it is used to store all SIDEKIT’s objects such as Mixtures, StatServers, Keys, Ndx, IdMaps and feature files.
The hierarchical architecture of HDF5 files allows to save several datasets or groups in the same file.
Note
that a dataset can have different reallities. It can be a scalar value, a matrix or a complete sub directory including several sub-datasets.
Saving features per audio channel¶
Consider the case where your audio files have one or several audio channels (like stereo files). In this example, we consider that all the features extracted from a single audio channel are saved into one single HDF5 file.
This architecture is illustrated by the following figure:
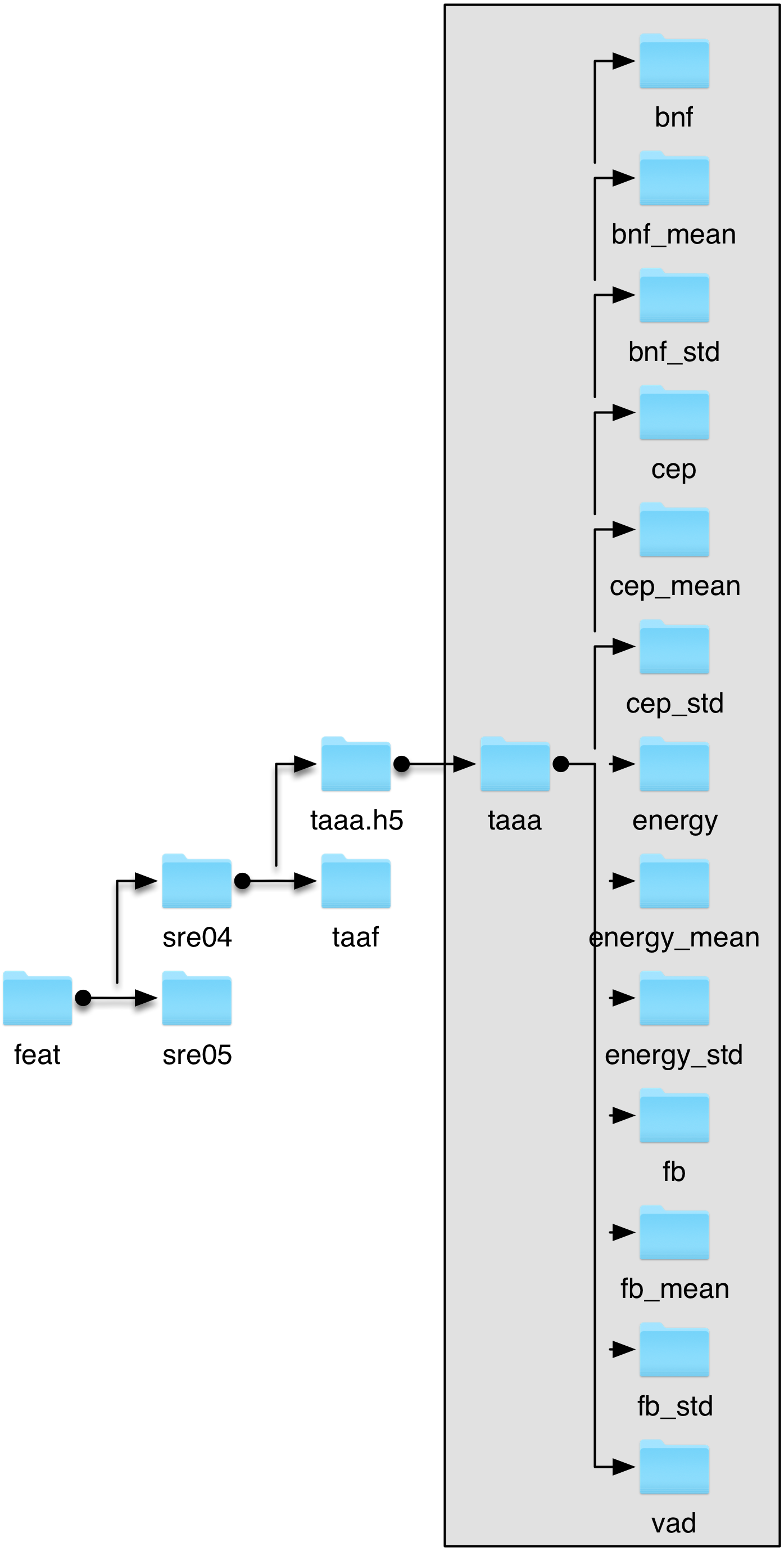
First HDF5 structure¶
In this example, we see two parts in the architecture. The part in the grey box exists inside the HDF5 file while the part outside the grey box is part of the OS file architecture.
In this case, we stored all our feature files in one directory: feat that includes two sub-directories: sre04 and sre05. In sre04, we store two HDF5 files: taaa.h5 and taaf.h5.
In our example, each of those file has the same internal organization. It includes 13 datasets (in the sense of HDF5 datasets); which are:
bnf for the bottleneck features
bnf_mean the mean vector of selected bottleneck features
bnf_std the standard deviation vector of the selected bottleneck features
cep cepstral coefficients
cep_mean the mean vector of selected cepstral coefficients
cep_std the standard deviation vector of the selected cepstral coefficients
energy a vector of log-energy values
energy_mean a scalar: mean value of the log-energy vector
energy_std a scalar: standard deviation of the log-energy vector
fb the filter-bank coefficients
fb_mean the mean vector of selected filter-bank coefficients
fb_std the standard deviation vector of the selected filter-bank coefficients
vad a vector of binary values that indicates which are the selected frames
Saving features for a collection of audio files¶
In a second example, we chose tho store all features extracted from a collection of audio data in a single HDF5 file. That is: parameters extracted from all audio channels from all audio files from this collection will be store in the same HDF5 file.
An example of this structure can be seen on the following figure:
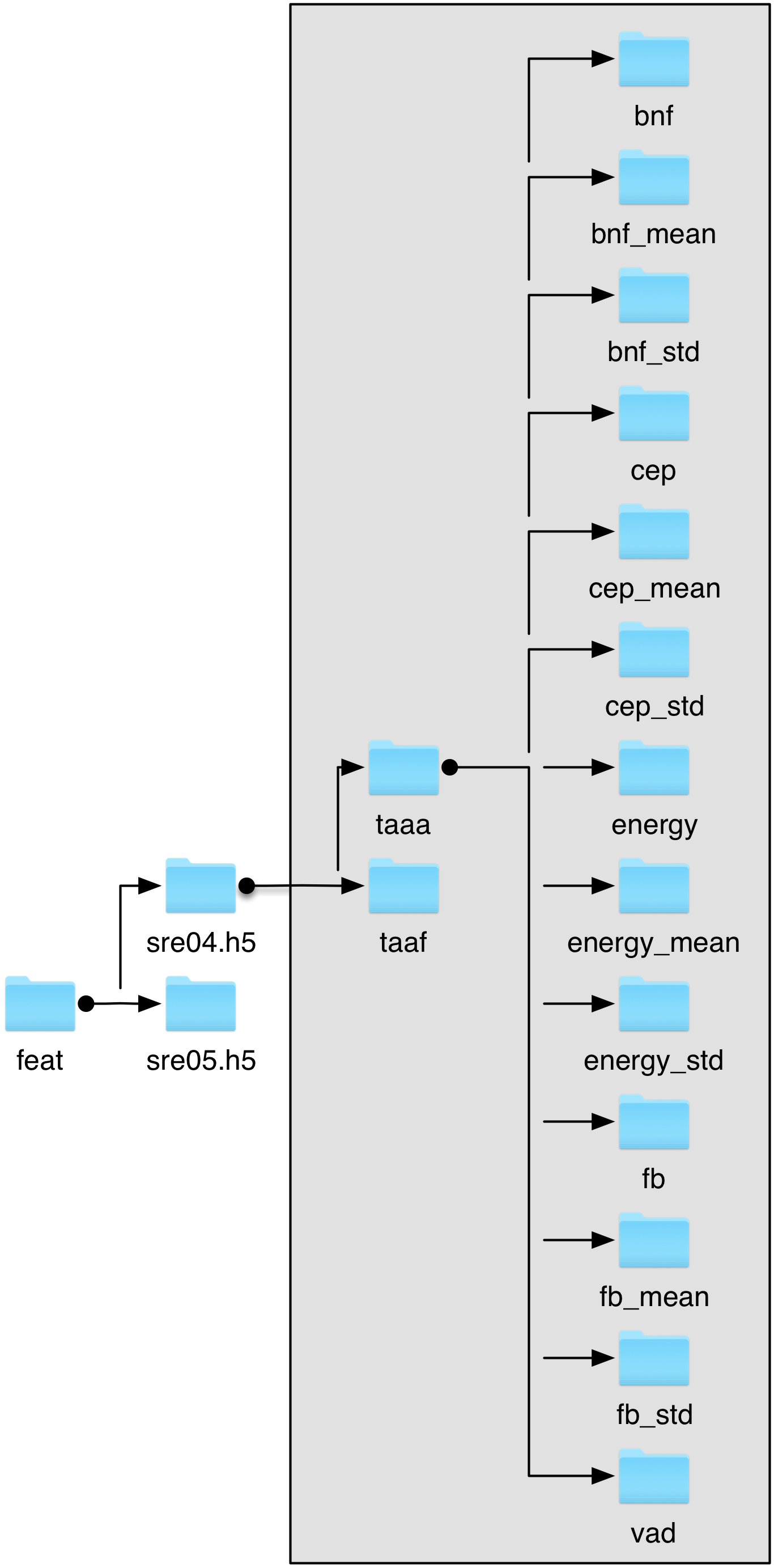
Another example of HDF5 structure¶
In this example, the architecture is exactly the same as the one in the firs example (see above), except that a single HDF5 file: sre04.h5 contains features extracted from two audio channels: taaa and taaf. The two corresponding datasets in the sre04.h5 file have the same structure as the two separated HDF5 files from the previous example (taaa.h5 and taaf.h5).
Modifications in the Python code that will use the two structures are minor but may have a great impact in term of usability and speed depending on your constraints.
Loading features from a HDF5 file¶
One advantage of storing different types of features into a single file is that we can load, at run time, one or several types of feature and combine them to feed our speaker/language recognition system. For instance, we will see in the following tutorials that is it easy to load the log-energy and cepstral coefficients or to combine the log-energy with the 10 first filter-bank coefficients.