2. The FeaturesExtractor object¶
The FeaturesExtractor takes audio files (WAV, SPHERE, raw PCM…) and returns feature files in HDF5 format (log-energy, cepstral coefficients, filter-bank coefficient, bottleneck features).
The interface of the FeaturesExtractor is as simple as possible as the main focus here is to define the parameters of the feature extraction and not to process complex operations on features.
Option |
Value (default is bold) |
|
|---|---|---|
audio_filename_structure |
None, a string |
Structure of the input audio file name if recurrent. In case all input file name have the same structure with a different identifier, the filename is completed at run time by adding the identifier into the filename structure (see examples below). |
feature_filename_structure |
{}, a string |
Structure of the output feature filename. In case all output file name have the same structure with a different identifier, the filename is completed at run time by adding the identifier into the filename structure (see examples below). |
sampling_frequency |
8000, integer |
Sampling frequency of the input audio file. In case this value is lower than the real sampling frequency, the input is downsampled to match this value. |
lower_frequency |
None, float |
Lower frequency of the frequency filter bank scale. |
higher_frequency |
None, float |
Higher frequency of the frequency filter bank scale. |
filter_bank |
None, “lin” or “log” |
Type of frequency filter bank, can be “lin” for linear scale and “log” for MEL scale. |
filter_bank_size |
None, integer |
Number of filter in the filter bank |
window_size |
None, float |
Size of the FFT window in seconds. |
shift |
None, float |
Shift of the FFT window between two samples, in seconds. |
ceps_number |
None, integer |
Number of cesptral coefficients retained. |
vad |
None, “snr”, “energy”, “percentil, “dnn”, “lbl” |
Type of Voice Activity Detection algorithm to apply. “lbl” reads from labels from file. |
snr |
None, float |
Parameter of the “snr” VAD. |
pre_emphasis |
0.97, float between 0 and 1 |
Value used for the pre-emphasis filtering. |
save_param |
[“energy”, “cep”, “fb”, “bnf”, “vad”], list |
Type of features to store in the output HDF5 file. The types are given in a Python list. |
keep_all_features |
None, boolean |
If False, only store feature frames selected by the VAD. If True, store all frames. |
Extract features with standardized input and output filenames¶
In this example, we extract features from audio files which names follow the patttern:
audio/nist_2004/{filename}.sph where filename is a unique identifier that will be refered as show in the rest of the documentation
See figure below:
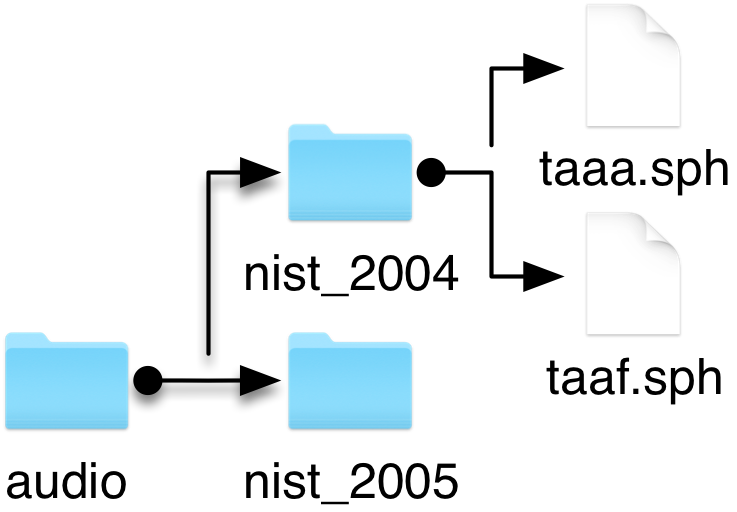
Input audio files.¶
The features will be stored in files with filename pattern:
feat/sre04/{filename}.h5, see structure below:
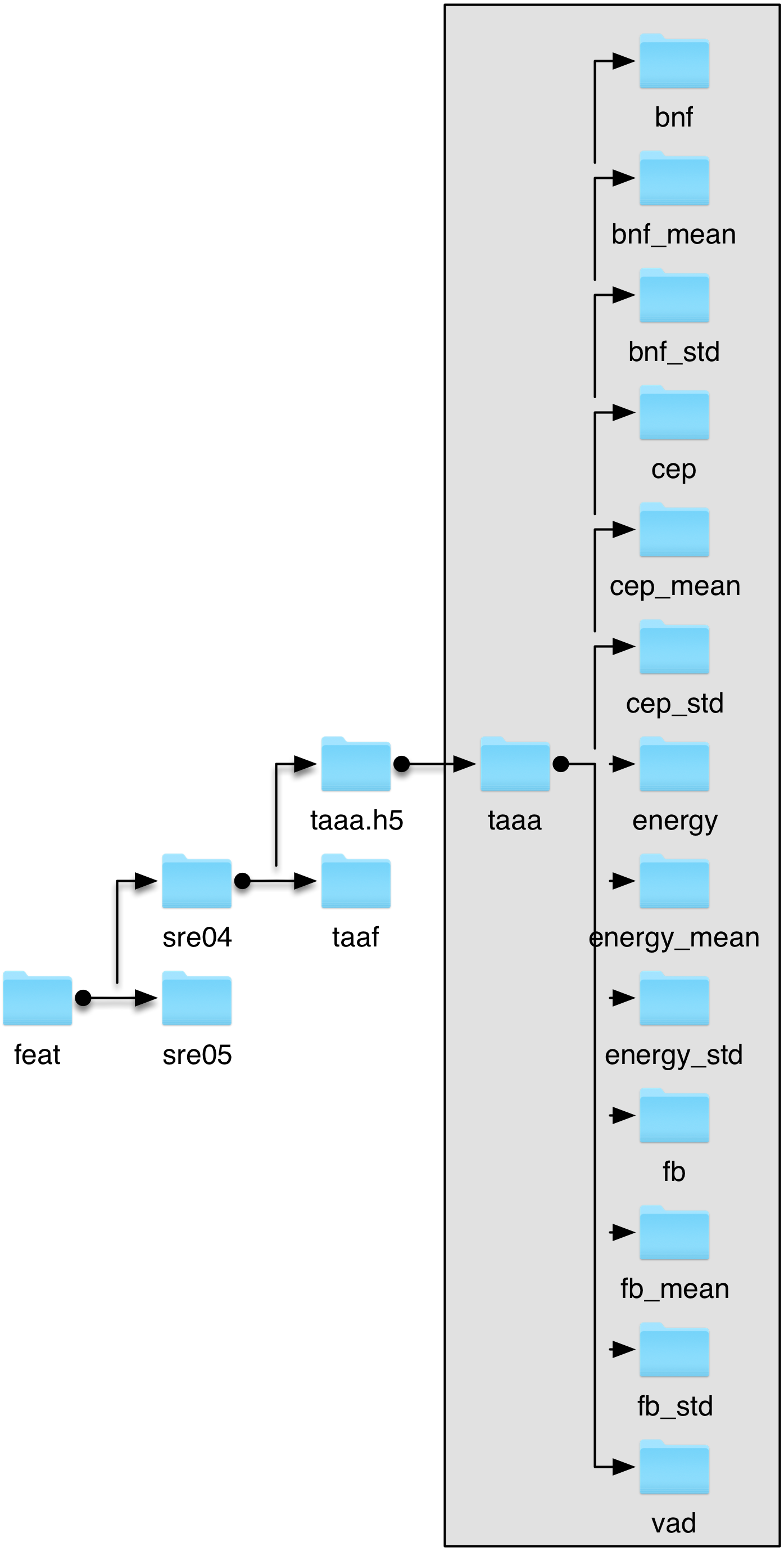
Output HDF5 files¶
The FeaturesExtractor is instantiated with the following code:
extractor = sidekit.FeaturesExtractor(audio_filename_structure="audio/nist_2004/{}.sph",
feature_filename_structure="feat/sre04/{}.h5",
sampling_frequency=None,
lower_frequency=200,
higher_frequency=3800,
filter_bank="log",
filter_bank_size=24,
window_size=0.025,
shift=0.01,
ceps_number=20,
vad="snr",
snr=40,
pre_emphasis=0.97,
save_param=["vad", "energy", "cep", "fb"],
keep_all_features=True)
As you can see, the audio_filename_structure and feature_filename_pattern will completed at run time and the call of:
extractor.save("taaa")
will process the file audio/nist_2004/taaa.sph and store features in feat/sre04/taaa.h5.
In case you’re not interested in saving the parameters to disk, you can ask your FeaturesExtractor to return a HDF5 file handler as follow:
fh = extractor.extract("taaa")
In this case, fh is a HDF5 file handler.
It is also possible to process a list of audio files with a single command. The processing of the audio files can also be parallelized to speed up the process. The command is as follow:
show_list = ["taaa", "taaf"]
channel_list = [0, 0]
extractor.save_list(show_list=show_list,
channel_list=channel_list,
num_thread=10)
In this example, the processing of the audio file list will be parallelized on 10 process (useless here as there are only 2 files but you get the idea…).
Extract features with non-standardized filenames¶
In case your input audio file names or output feature file names don’t follow any pattern, it is possible to specify the complete input filename and complete output filname as follow.
For instance, you want to process the following audio files such that:
Input audio filename |
Output feature filename |
|---|---|
audio/sre04/taaa.sph |
feat/nist/taaa.h5 |
data/nist2005/xllb.sph |
output/nist/xllb_a.h5 |
Let define a new FeaturesExtractor to process those files:
extractor = sidekit.FeaturesExtractor(audio_filename_structure=None,
feature_filename_structure=None,
sampling_frequency=None,
lower_frequency=200,
higher_frequency=3800,
filter_bank="log",
filter_bank_size=24,
window_size=0.025,
shift=0.01,
ceps_number=20,
vad="snr",
snr=40,
pre_emphasis=0.97,
save_param=["vad", "energy", "cep", "fb"],
keep_all_features=True)
And process the first file to save the features to disk:
extractor.save(show="taaa",
channel=0,
input_audio_filename="audio/sre04/taaa.sph",
output_feature_filename="feat/nist/taaa.h5")
extractor.save(show="xllb",
channel=0,
input_audio_filename="data/nist2005/xllb.sph",
output_feature_filename="output/nist/xllb_a.h5")
Same thing without saving to disk:
fh = extractor.extract(show="taaa",
channel=0,
input_audio_filename="audio/sre04/taaa.sph",
output_feature_filename="feat/nist/taaa.h5")
In order to process a list of files you’ll run:
show_list = ["taaa", "xllb"]
input_file_list = ["audio/sre04/taaa.sph", "data/nist2005/xllb.sph"]
output_feature_list = ["feat/nist/taaa.h5", "output/nist/xllb_a.h5"]
extractor.save_list(show_list=show_list,,
channel_list=channel_list,
num_thread=10)
Of course you can combine input filenames without pattern and output filenames with patterns or the opposite.
Note
When using input or output filenames without patterns, you see that the show parameter is still used.
Indeed, this parameter is used in the structure of the HDF5 file. The output feature file will look like:
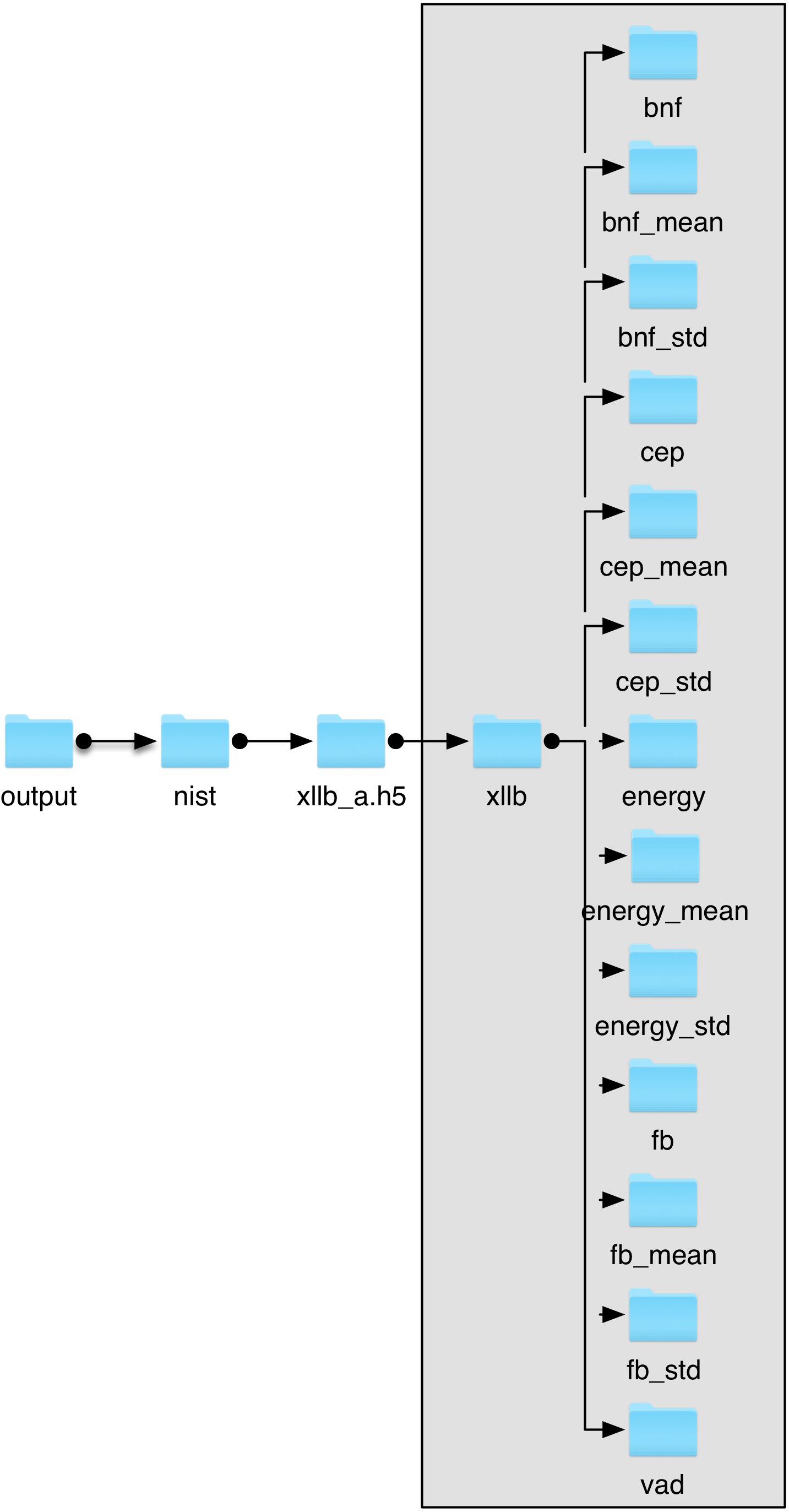
Structure of the HDF5 feature file.¶
As you can see, the show identifier is used inside the HDF5 file in order to allow storage of several feature sets in a single file.
Note that it also exists although you store one single feature set in a HDF5 file.