Run a GMM-UBM system¶
This script run an experiment on the male evaluation part of the RSR2015 database. The protocols used here is based on the one described in [Larcher14]. In this version, we only consider the non-target trials where impostors pronounce the correct text (Imp Correct).
The number of Target trials performed is then - TAR correct: 10,244 - IMP correct: 573,664
[Larcher14] Anthony Larcher, Kong Aik Lee, Bin Ma and Haizhou Li, “Text-dependent speaker verification: Classifiers, databases and RSR2015,” in Speech Communication 60 (2014) 56–77
Input/Output¶
Enter:¶
the number of distribution for the Gaussian Mixture Models the root directory where the RSR2015 database is stored
Generates the following outputs:¶
a Mixture in HDF5 format (ubm)
a StatServer of zero and first-order statistics (enroll_stat)
a StatServer containing the super vectors of MAP adapted GMM models for each speaker (enroll_sv)
a score file
a DET plot
First, loads the required PYTHON packages:
import sidekit
import os
import sys
import multiprocessing
import matplotlib.pyplot as mpl
import logging
import numpy as np
logging.basicConfig(filename='log/rsr2015_ubm-gmm.log',level=logging.DEBUG)
Set your own parameters¶
distribNb = 512 # number of Gaussian distributions for each GMM
rsr2015Path = '/lium/corpus/audio/tel/en/RSR2015_v1/'
# Default for RSR2015
audioDir = os.path.join(rsr2015Path , 'sph/male')
# Automatically set the number of parallel process to run.
# The number of threads to run is set equal to the number of cores available
# on the machine minus one or to 1 if the machine has a single core.
nbThread = max(multiprocessing.cpu_count()-1, 1)
Load IdMap, Ndx, Key from HDF5 files and ubm_list¶
Note that these files are generated when running rsr2015_init.py:
print('Load task definition')
enroll_idmap = sidekit.IdMap('task/3sesspwd_eval_m_trn.h5')
test_ndx = sidekit.Ndx('task/3sess-pwd_eval_m_ndx.h5')
key = sidekit.Key('task/3sess-pwd_eval_m_key.h5')
with open('task/ubm_list.txt') as inputFile:
ubmList = inputFile.read().split('\n')
Process the audio to save MFCC on disk¶
logging.info("Initialize FeaturesExtractor")
extractor = sidekit.FeaturesExtractor(audio_filename_structure=audioDir+"/{}.wav",
feature_filename_structure="./features/{}.h5",
sampling_frequency=16000,
lower_frequency=133.3333,
higher_frequency=6955.4976,
filter_bank="log",
filter_bank_size=40,
window_size=0.025,
shift=0.01,
ceps_number=19,
vad="snr",
snr=40,
pre_emphasis=0.97,
save_param=["vad", "energy", "cep"],
keep_all_features=False)
# Get the complete list of features to extract
show_list = np.unique(np.hstack([ubmList, enroll_idmap.rightids, np.unique(test_ndx.segset)]))
channel_list = np.zeros_like(show_list, dtype = int)
logging.info("Extract features and save to disk")
extractor.save_list(show_list=show_list,
channel_list=channel_list,
num_thread=nbThread)
Create a FeaturesServer¶
From this point, all objects that need to process acoustic features will do it through a FeaturesServer. This object is initialized here. We define the type of parameters to load (log-energy + cepstral coefficients) and the post-process to apply on the fly (RASTA filtering, CMVN, addition iof the first and second derivatives, feature selection).
# Create a FeaturesServer to load features and feed the other methods
features_server = sidekit.FeaturesServer(features_extractor=None,
feature_filename_structure="./features/{}.h5",
sources=None,
dataset_list=["energy", "cep", "vad"],
mask=None,
feat_norm="cmvn",
global_cmvn=None,
dct_pca=False,
dct_pca_config=None,
sdc=False,
sdc_config=None,
delta=True,
double_delta=True,
delta_filter=None,
context=None,
traps_dct_nb=None,
rasta=True,
keep_all_features=False)
Train the Universal background Model (UBM)¶
print('Train the UBM by EM')
# Extract all features and train a GMM without writing to disk
ubm = sidekit.Mixture()
llk = ubm.EM_split(features_server, ubmList, distribNb, num_thread=nbThread, save_partial=True)
ubm.write('gmm/ubm.h5')
Compute the sufficient statistics on the UBM¶
Make use of the new UBM to compute the sufficient statistics of all enrolement sessions that should be used to train the speaker GMM models. An empty StatServer is initialized from the enroll_idmap IdMap. Statistics are then computed in the enroll_stat StatServer which is then stored in compressed pickle format:
print('Compute the sufficient statistics')
# Create a StatServer for the enrollment data and compute the statistics
enroll_stat = sidekit.StatServer(enroll_idmap,
distrib_nb=512,
feature_size=60)
enroll_stat.accumulate_stat(ubm=ubm,
feature_server=features_server,
seg_indices=range(enroll_stat.segset.shape[0]),
num_thread=nbThread)
enroll_stat.write('data/stat_rsr2015_male_enroll.h5')
Adapt the GMM speaker models from the UBM via a MAP adaptation¶
Train a GMM for each speaker. Only adapt the mean supervector and store all of them in the enrol_sv StatServer that is then stored to disk:
print('MAP adaptation of the speaker models')
regulation_factor = 3 # MAP regulation factor
enroll_sv = enroll_stat.adapt_mean_map_multisession(ubm, regulation_factor)
enroll_sv.write('data/sv_rsr2015_male_enroll.h5')
Compute all trials and save scores in HDF5 format¶
print('Compute trial scores')
scores_gmm_ubm = sidekit.gmm_scoring(ubm,
enroll_sv,
test_ndx,
features_server,
num_thread=nbThread)
scores_gmm_ubm.write('scores/scores_gmm-ubm_rsr2015_male.h5')
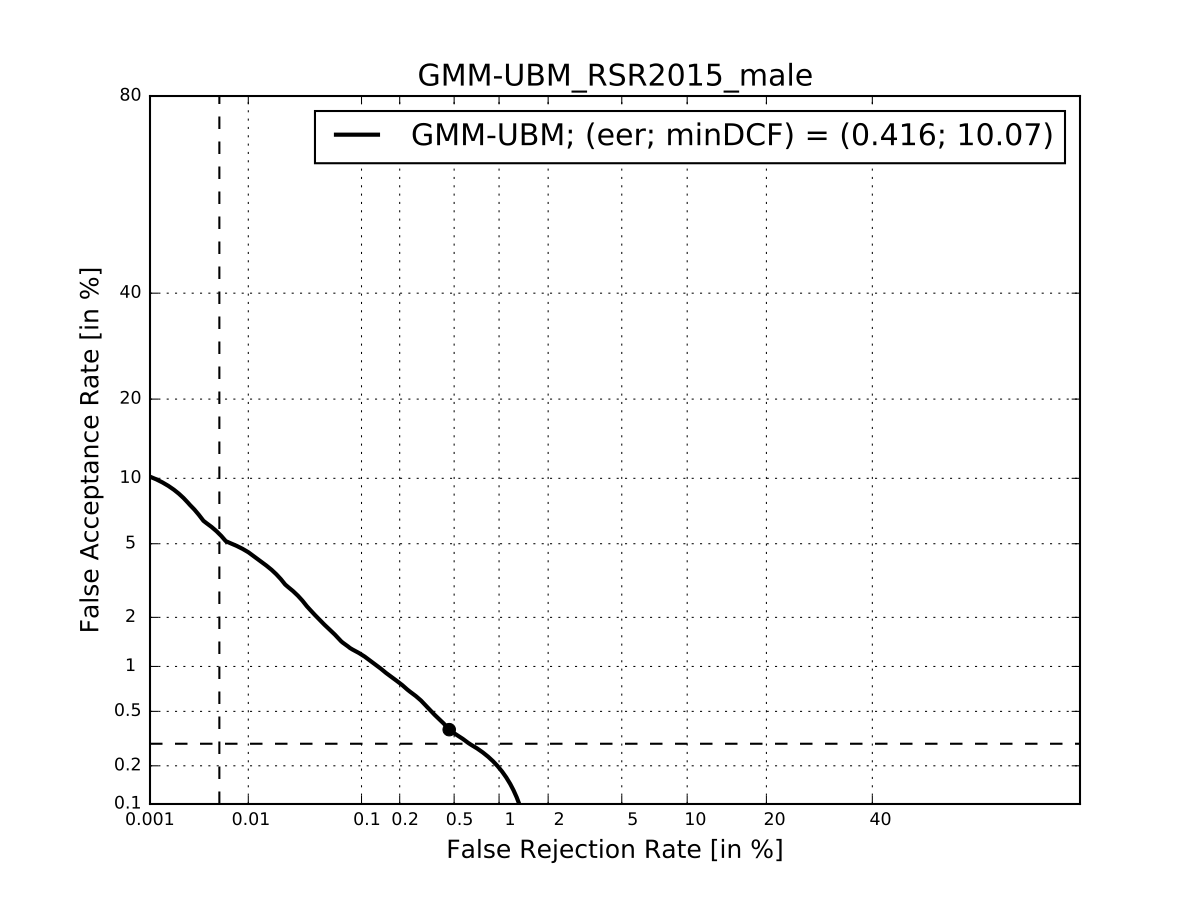
Plot DET curve and compute minDCF and EER¶
print('Plot the DET curve')
# Set the prior following NIST-SRE 2008 settings
prior = sidekit.logit_effective_prior(0.01, 10, 1)
# Initialize the DET plot to 2008 settings
dp = sidekit.DetPlot(window_style='sre10', plot_title='GMM-UBM_RSR2015_male')
dp.set_system_from_scores(scores_gmm_ubm, key, sys_name='GMM-UBM')
dp.create_figure()
dp.plot_rocch_det(0)
dp.plot_DR30_both(idx=0)
dp.plot_mindcf_point(prior, idx=0)
Compute equal error rate and minDCF, plot the DET curve.
print('Plot DET curves')
prior = sidekit.logit_effective_prior(0.001, 1, 1)
minDCF, Pmiss, Pfa, prbep, eer = sidekit.bosaris.detplot.fast_minDCF(dp.__tar__[0], dp.__non__[0], prior, normalize=True)
print("UBM-GMM 128g, minDCF = {}, eer = {}".format(minDCF, eer))
The following results should be obtained at the end of this tutorial: